Listening to Tony Seba talk about what he sees as the inevitability of autonomous electric fleet vehicles taking over urban transportation fascinated me from start to finish: see on Youtube.
Category Archives: Uncategorized
My First Alexa Skill: AI Isn’t Taking Over the World Yet
Tony Stark inspired me. Why exercise my fingers all day long when I could just ask my Amazon Echo for information or to do something? Well…
AWS boldly claims you can “Develop an Alexa Skill in under 5 minutes”” https://developer.amazon.com/alexa-skills-kit/alexa-skill-quick-start-tutorial.
I gave it a go, and was able to get the Alexa equivalent of “Hello World” running in, say, 15 minutes. If you were racing, didn’t care to understand why anything worked, and didn’t want to make any changes to the sample application, 5 minutes isn’t really an unreasonable claim. Playing with it for an hour gave me a decent understanding of what Alexa can and probably can’t do. But being able to interact with a device already on my desk which I’ve never directly programmed in just a few minutes is actually pretty cool.
However, reports of the coming AI apocalypse have been greatly overstated.
The Alexa service certainly has cool voice recognition. Ambient room sounds are sorted from human voices. phonemes are identified and rolled up into words. Words are filtered based on context–maybe– and sentences built. Alexa can then identify keywords to figure out to which service to route the request. All cool.
That’s about as far as the smarts go, however. The developer of a “skill” gets exactly 0 help in interpreting the semantics of English sentences– and yes, Alexa understands only English. The skill developer has to specify the exact words the user might speak to your program. EVERY. SINGLE. WORD. There are no smarts whatsoever. Moreover, your skill isn’t passed any context about how the parsing of phonemes went. If Alexa (without any context) decided the user said “Plato” instead of “Play-Doh”, your skill will either fail to understand, or you’ll have to guess ahead of time what Alexa might have misunderstood.
Not smart yet.
I Don’t Ever Want to Write SQL Again
Actually, I think SQL is great. It’s one of the earliest declarative languages, handing the work of figuring out how best to get the desired result to where it should be— the computer. It’s also so well designed that it’s still in widespread use today in relationship databases, with little complaint.
No, my problem is that almost all of the SQL that I’m called upon to write has to live within another programming language, like Java or Python. Most language environments support connection to a SQL data source in some form or another. This generally means writing additional wrapper code, but still placing SQL in local strings.
The consequence of this lack of support is that
- developer tools that can help me assure that my types and logic are correct don’t help me
- I can’t directly execute the SQL code, because it’s formatted in my source language, wrapped in quotes, and formatted incorrectly.
- I can’t easily refactor my SQL.
A typical query might look like this:
String query = "SELECT firstName, lastName, id FROM my_table WHERE state = ? AND category = ?";
try {
PreparedStatement stmt = connection.prepareStatement(query);
stmt.setString(1, state);
stmt.setInt(2, category);
ResultSet rs = stmt.executeQuery();
List<Record> records = new ArrayList<>();
while (rs.next()) {
records.append(new Record(rs.getString(1), rs.getString(2));
}
return records;
} catch (SQLException e) {
throw new RuntimeException(e);
}
This is dumb. Dumb like burning fossil fuels to power passenger vehicles. Expedient once, perhaps, but on the wrong side of history.
The code could look like this:
return l.stream().filter(b-> b.hasState(state)).filter(b -> b.inCategory(category).collect(Collectors.toList());
How about that? If SQL queries were built into Java 8 streams, the actual SQL could be generated on the fly within the streams mechanism, allowing optimization of the number of items queried on the client side. The set of items being queried could then be incorporated into Java refactoring.
Why stop there? In debugging at least, SQL errors could be handled much more intelligently. Actually query the schema of the database and propose solutions! Check that the model in use at the client is the model actually in use at the database server.
jOOQ is the closest tool to actually self-writing SQL I know of. Still looking for other solutions.
How Much of Language Do We Recognize?
In 1971, Albert Mehrabian published a book Silent Messages, in which he discussed his research on non-verbal communication by salespeople. He concluded that prospects based their assessments of credibility on factors other than the words the salesperson spoke—the prospects studied assigned 55 percent of their weight to the speaker’s body language and another 38 percent to the tone and music of their voice. They assigned only 7 percent of their credibility assessment to the salesperson’s actual words.
A Google search quickly indicates that the prevailing view of this assessment is somewhere around “total horseshit”. A more lengthy Google search indicates there’s no prevailing consensus on even what measurement standard is appropriate for a quantitative standard for “perception”, let alone “understanding”.
Subjectively, though, this is easy to try out. Watch a foreign language movie without subtitles, and you’ll immediately get a strong sense. I watched Lion. The gist is that a five-year old falls asleep on a train and ends up stranded in Calcutta, and adult adoptee (Dev Patel) tries to find his family. The movie is structured in roughly chronological order, and I watched the early India scenes with the five-year-old in Hindi and Bengali. [I admit, I totally had to look that up. Not only do I not recognize either language, they’re not aurally distinct enough to this Western ear for me to notice without subtitles that I ought to be switching dictionaries]
My short analysis: between tone, facial expressions, recognition of repeated phrases, and recognizing social interactions, I didn’t miss even a nuance of plot-relevant communication without the benefit of English. I even could have given a sloppy but accurate translation of every scene, except little Saroo telling his sketchy would-be adopter that his Mom “carries rocks” for a living. I reviewed the first 35 minutes again with subtitles to confirm my suspicion: at least in movie-making, the specifics of language are only costumes hung on the structure of human communication. Details are extremely handy, but are only the inker to the cartoonist.
I’ve had the real-life equivalent as well. On a vacation in Mexico, my very-smart daughter was our expert in Spanish. While having an organic grammar and vocabulary reference (and why not, roaming data in Mexico is expensive), our communications go-to was an improvised evaluation of “what’s the interest of the other party” and “what do we want?” Simply triaging what the interaction was about was at least half way there, without formal language of any kind. Is this an ordinary transaction? Great, the price is probably set and we just need to make our desires understood: “one Big Mac, please”. Is this a negotiation? Even better, understanding market dynamics is international: “Okay, we’ll negotiate a great price for our gondola, but we understand you can’t put our new friends on the same boat without screwing over your fellow sellers”. Eazy Peazy.
Remembering Fail-Safe
The description “fail safe” is commonly used to mean something foolproof, or a system with backup systems to prevent failure. In other words, “safe from failure”.
That’s a shame, since we have plenty of words that already mean that. My dictionary defines fail-safe as … a system … that insures safety if the system fails to operate properly. The original meaning meant “safe in case of failure”. Things break. How do we head off catastrophe?
Real World examples
The TCP network protocol “guarantees” delivery, but it’s fail-safe. If a packet can’t be delivered, as happens, the connection is dropped rather than either accepting partial or corrupted data.
In the movie Die Hard, the engineers of Nakatomi Plaza decided that safety meant that in the event of a power failure all the security systems of the building would be dis-abled. In the movie that meant the bad guys could get into the vault. In the real world, that decision would prevent people from being locked into the building.
After thousands of deaths resulting from train accidents, train car brakes are now engaged by default. A pressure line powered by the locomotive pulls the brake pads away from the wheels. In the event that any of the braking system (the non-braking system?) fails, the brakes are pressed against the wheels.
Airplanes use positive indicators for the status of important functions such as the landing gear being down. Instead of an error light if the gear has failed, there’s a no-error light if the gear is locked. Should the sensor, wiring, or bulb fail, the indication is that gear is not down. Better to have gear down and think it’s not than think it is when it isn’t.
Value in software
This idea that we should expect failure isn’t novel, it’s called testing. But arguably the primary purpose of testing is to identify defects in the software to avoid failure in production. Is there value in assuming that we won’t be successful at preventing every possible anomalous condition, including that our code does what we expect? Consider the questions that fail safe raises?
What can fail?
Your software has bugs in it. Networks go down. You may get broken input. You may get correct input that breaks your system because you didn’t know the correct format. You may get data in the wrong order. Software you didn’t write but you’re counting on may fail.
What is “safe”?
What’s the best result when failure happens? Roll back a transaction? Immediately kill a system? Display an error? Throw an exception?
How we get back from “safe” to operational again?
Once having decided what failure means and how to entire a safe mode, we may not have asked ourselves before how to get things going again. If we reject entry of a file that contains erroneous data, how do we notify someone to deal with that? How do we get it out of a queue to be processed again?
The Advantages of Convention over Configuration
Several popular frameworks have as a core design principle that “convention” is preferred over “configuration”.
I’ve come to think that they’ve actually understated the case. In fact, our development team has made significant strides in identifying not only causes of defects, but also the factors that slow development in exchange for reducing defects in the first place.
One of the top issues on the latter list is what we’ve been calling the “arbitrary decision”. If a given technical challenge is hard, that can actually simplify development. Either the first solution we find is a good one, since we save time by avoiding looking for additional solutions, which might not even exist. Or there may be a clear best solution, or even only one that will actually work.
This “arbitrary decision” is exactly what’s referred to as “convention”. Every convention that’s already been decided both reduces defects and saves developer time.
Defects are reduced because:
- Developers have fewer decisions to make, saving focus for important problems
- Mismatches between modules or components are reduced
- The code visually reflects the standard, making deviation apparent
Speed of development is increased simply because there are fewer decisions to make.
Here are some examples of conventions that have benefitted us:
- Code formatting standard. We really didn’t fight over this, as the development team is aware of the benefits of not fighting about it. We agreed our standard is “good enough”, so we can move on.
- Variable naming conventions, including capitalization of common names in our domain space.
- Which of the several libraries that provide the same functionality, such as Base64 conversion.
- Coding language versions: do we rely on features of newer implementations or make code backward-compatible
Incremental Database Migrations
One of the causes of headaches for active development is database migrations. Code that requires new tables or new columns in existing tables simply won’t work if the database migration hasn’t been applied.
This is different from code, which could (safely) use introspection to see if a field in a class exists, or simply just recompile the entire project monolithically. New, unused members can safely be added, and can even be safely discarded when using a compiling language like C# or Java.
It is not even safe to add additional columns, as we discovered in production recently:
When adding a new column to a table which has an identical name to an existing column in another table, and those tables are joined, SQL queries can fail because the selector field or the WHERE clauses may become ambiguous.
So, another point for using an ORM.
Parallels Desktop v. VMWare Fusion for Linux
sudoParallels (parallels website) and VMWare (VMWare website) have been releasing new updates and fighting head-to-head for the business of people roughly like me for years. For a moment there, the competition was so fierce that the cheapest way for me to get a new Parallels license was to buy a copy of VMWare via their super-cheap “competitive upgrade” pricing, and then use my new VMWare license to get a competitive upgrade to the newest Parallels product.
The feature set and performance have always been, according to reviews and my own experience, pretty comparable. And both companies have been aggressively pushing for performance improvements and marketing wins for those virtualizing Microsoft Windows.
My primary purpose for virtualization is in running Linux, which is a use case that neither company is particularly advertising. That means that the real feature sets and performance comparisons aren’t crystal clear. Ergo, my comparison of the anomalies, wins, and losses between the two (nearly) most current products, from the experience of a Linux virtualizer:
[table id=2 /]
Some problems are cropping up with VMWare in the process of verifying this information under Sierra.
“Shared folders will not be available in the virtual machine until VMware Tools is installed and running.” appears on the Sharing tab under settings. This would be a reasonable error except:
- It appears even if the Tools are installed
- There’s not a good indication as to whether the Tools are installed or not: there is some VMWare functionality automatically installed (somehow) into the virtual machine before the VMWare Tools installation process.
VMWare with Centos 7 is behaving inconsistently with multiple screens. With 3 Mac screens active, “Full Screen” along with not “Use Single Screen in Full Screen” results in a single virtual screen being mirrored across all 3 monitors. Fine, that’s what the directions for Fusion say, along with “you’ll have to make changes inside the virtual machine“. Well, fine, but:
- Directions, anywhere, anyone? Hello?
- I’m sure they mean, for CentOS, Settings, Displays
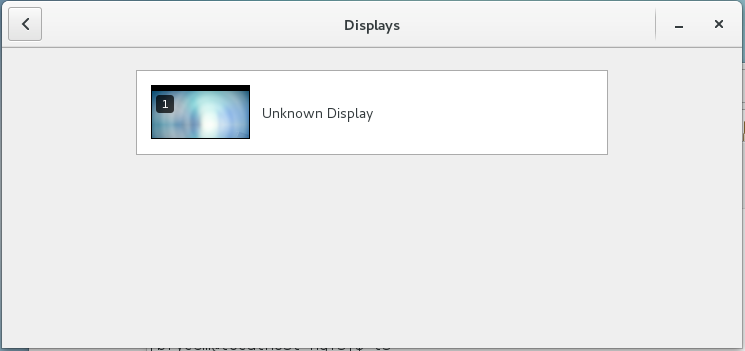
Great, I need to control the display settings here, making sure I’m not mirroring the only display Fusion offers. So, Fusion can’t provide multiple virtual displays through the VMWare Tools into Linux. I could buy that, though that would be a big disappointment. But NO, multiple displays actually are provided. If I tell Sierra to mirror one of my displays to another one, then I get TWO distinct virtual displays, which are assigned to my physical displays. Huh? On the third display I see my two virtual displays together. WTF?
The rules for Parallels on to which its TWO displays gets mapped seems to depend on which is the active Mac screen and from which screen you go full screen:
Screen 1 Active:
1 : 1 + 2
2: 2 + 1
3: 3 + 1
Screen 2 Active:
1: 1 + 2
2 : 2 + 1
3 : 3 + 2
Screen 3 Active:
2: 2 + 3
3: 3 + 1
Another Parallels issue is the persistent message on boot that “[Parallels Tools] You should log out of the graphical session to apply new Shared Profile settings. When you log in again, all host computer user folders will be unmapped from those in the virtual machine.” You’d think that rebooting would be sufficient to “log out of the graphical session”.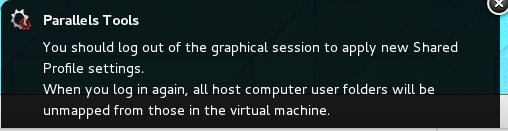
Another is that random mouse jumping occurs, usually moving from one screen to another.
WordPress Site Performance
UPDATE: database latency is by far the dominant factor in my site’s performance. Although using a dedicated Amazon RDS MySql instance, this site is on Dreamhost shared hosting. The latency to the AWS server means that even the 37 queries necessary for the basic front page view turned less than 100ms into a 6 second load.
Harder than you think it might be is having a grasshopper-fast web site. Here’s my research into what, exactly, “fast” means, and how to achieve it.
How Fast is Fast?
Here are some facts:
- IBM produced a paper distinguishing between >400ms and <400ms response time: http://daverupert.com/2015/06/doherty-threshold/ Computer response less than 400ms was “addicting”.
- This site recorded the median response time to stimulus is 266ms.
- Google’s PageRank algorithm says that page load speed is a factor in page ranking.
In short, faster is better, with no upper limit where benefits stop. My subjective experience is that there’s no instance I can generate for which improvement isn’t a benefit.
How Fast Is Your Site?
We’ve tested our sites with https://www.webpagetest.org/
What Are the Results?
All tested scenarios are with default WordPress install. The tested scenarios are:
- Dreamhost shared hosting with Dreamhost-provided MySQL
- AWS EC2 micro instance with local MySQL
- Dreamhost DreamCompute instance
[table id=3 /]
There are a couple of big surprises here. The first is that a shared hosting site isn’t so bad, all in all. First byte time is a couple hundred milliseconds slower than on a dedicated machine. Another is that the dedicated hosting time to complete file delivery is much slower than for shared hosting.
The biggest surprise is that the ratings for hosting from WebPageTest weight first byte response time so highly that the dedicated host is given a “B” grade, but shared hosting an “F”. Can’t tell you from these numbers how I would subjectively rate the experience.
Considering AWS RDS MySQL
Amazon AWS RDS costs:
| Payment Option | Upfront | Hourly | Monthly* | Effective Hourly** | Effective Monthly | On-Demand |
|---|---|---|---|---|---|---|
| No Upfront | $0 | $.017 | $10.22 | $0.014 | $10.08 | $0.017 per Hour, $12.24/month |
| Partial Upfront | $51 | $.006 | $4.38 | $0.012 | $8.57 | |
| All Upfront | $102 | $.000 | $0.00 | $0.012 | $8.50 |
Some common things you might want to be able to do:
Change the size of a the storage after configuring the instance
Yes: http://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_ModifyInstance.MySQL.html